O que significa GLM?
GLM significa Modelos Lineares Generalizados. Estes modelos são usados em estatística quando se deseja predizer uma variável utilizando funções conhecidas das variáveis de predição. Dentro desta condição, o GLM é uma ferramenta estatística poderosa utilizada por pesquisadores no mundo inteiro.
Exemplo: Aumento salarial anual
Vamos explorar um exemplo em que um salário é aumentado todo ano e vamos predizer futuros salários.
# criando o ano dos dados de 2010 até 2020
ano = 2010:2020
# criando a variável salário base, a qual inicia-se com 1000 e aumenta 100 todo ano. Isto é, estamos supondo que o salário aumenta 100 cada ano
salario.base = seq(1000, # valor inicial
length.out = length(ano), # tamanho do vetor
by = 100) # aumento de cada elemento
# vamos definir um desvio salarial, o qual vai ser somado ao salário base para encontrarmos o salário real. Ou seja, conhecemos somente o salário real; não conhecemos o salário base que aumenta 100 a cada ano e desejamos encontrar esse aumento anual de 100
set.seed(2) # definindo a seed para podermos repitir essa simulação
desvio.salarial = rnorm(length(ano),
sd = 50) # desvio padrão do desvio salarial
salario.real = salario.base + desvio.salarial
# vamos plotar os dados para ver como eles se parecem
plot(ano, # x
salario.base, # y
type = 'l', # plot linha
xlab = "Ano", # nome do eixo x
ylab = "Salário", # nome do eixo y
lwd = 10, # espessura da linha
mgp=c(2.3,0.7,0), # aumenta a posição dos textos dos eixos
cex.lab = 1.4, # aumenta o tamanho do texto dos eixos
cex.axis = 1.4) # aumenta o tamanho dos textos dos números dos eixos
grid() # cria linhas guias
lines(ano, # x
salario.base, # y
lwd = 10) # espessura da linha
points(ano, # x
salario.real, # y
cex = 2, # tamanho dos pontos
pch = 16, # tipo dos pontos
col = "red") # cor dos pontos
# criando uma legenda
legend('topleft', # posição da legenda
c("Real", "Medida"), # texto na legenda
lwd = 7, # espessura das linhas na legenda
lty = c(1, 0), # tipos da linha na legenda
col = c('black', 'red'), # cores das linhas na legenda
pch = c(-1, 16), # tipo dos pontos
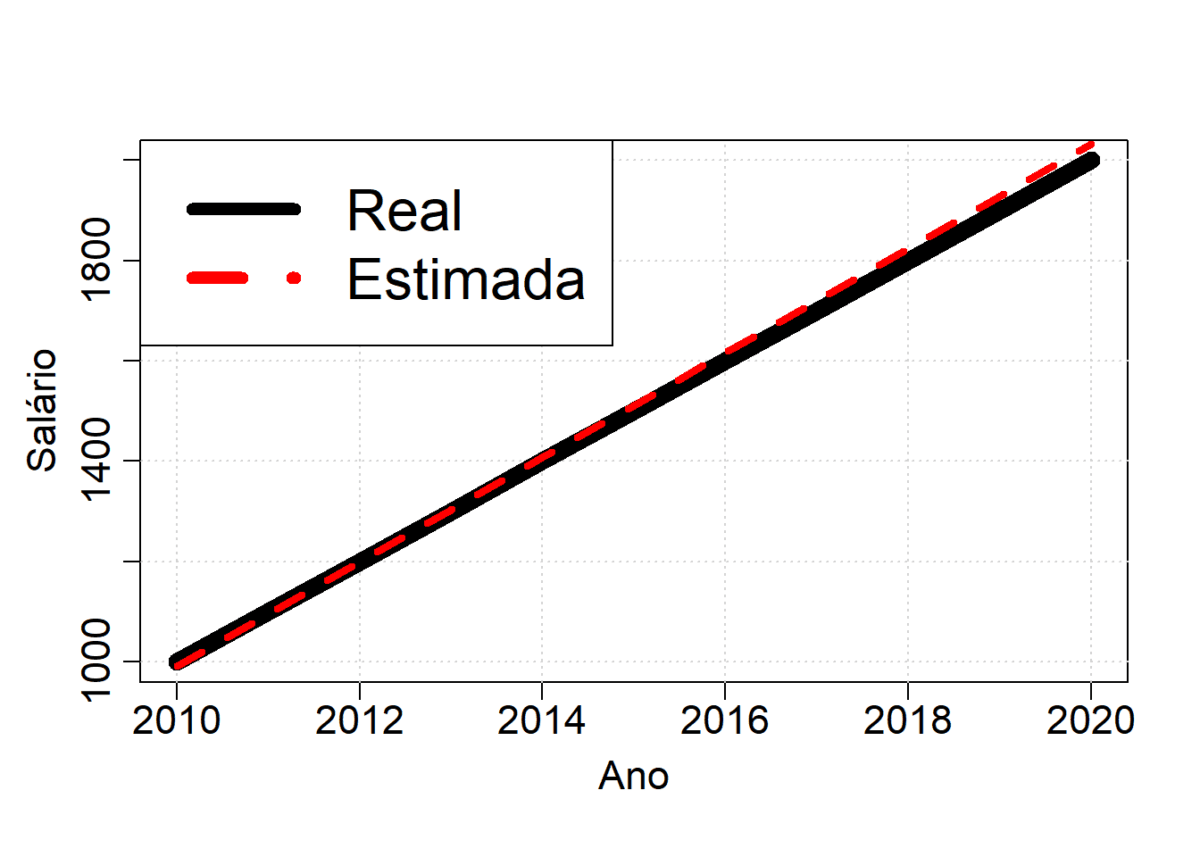
cex = 2) # aumenta o tamanho da legenda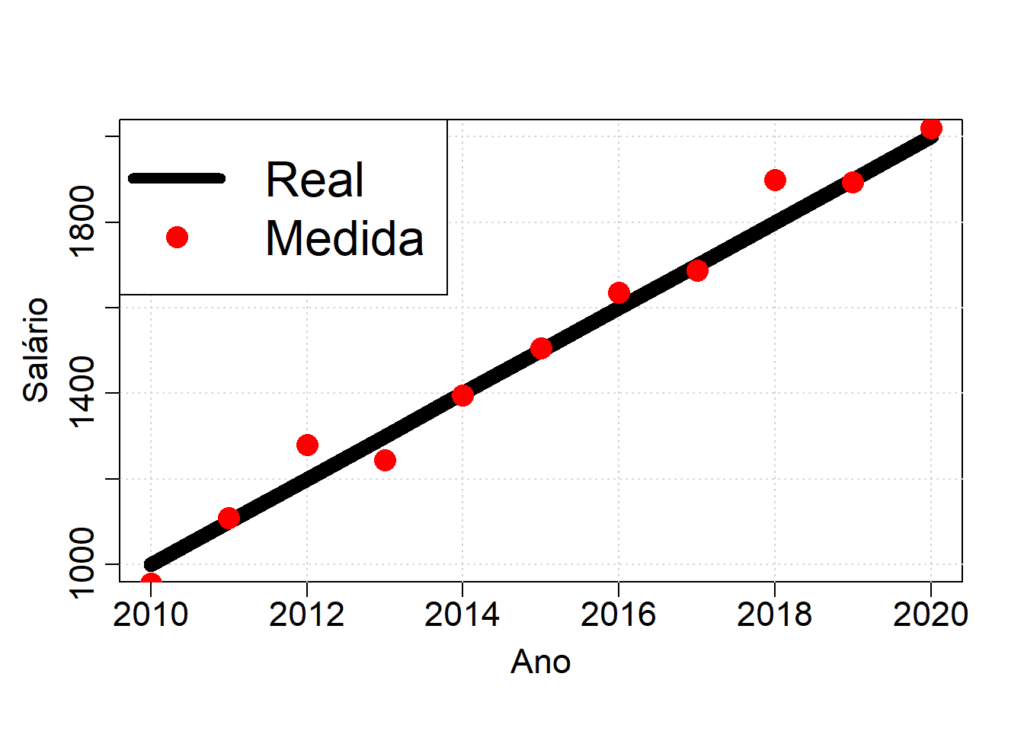
Agora que temos o conjunto de dados, podemos treinar nosso modelo GLM. Como o modelo que vamos treinar é simples, nós vamos utilizar a função lm do R.
# treinando o modelo GLM
modelo.GLM = lm (salario.real # o que queremos predizer
~ # a fórmula de predição vem depois do ~
ano) # o que vamos utilizar para predizer
# agora vamos olhar no sumário do modelo
summary(modelo.GLM)
##
## Call:
## lm(formula = salario.real ~ ano)
##
## Residuals:
## Min 1Q Median 3Q Max
## -59.80 -33.28 -11.15 16.99 80.22
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.083e+05 9.073e+03 -22.95 2.68e-09 ***
## ano 1.041e+02 4.503e+00 23.12 2.52e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 47.22 on 9 degrees of freedom
## Multiple R-squared: 0.9834, Adjusted R-squared: 0.9816
## F-statistic: 534.6 on 1 and 9 DF, p-value: 2.517e-09
# o modelo encontrou que o aumento anual é de 104 +- 4, que inclue o aumento anual do salário base 100
# vamos plotar o modelo e comparar com a função do GLM
salario.estimado = predict(modelo.GLM, data.frame(ano = ano))
plot(ano, # x
salario.base, # y
type = 'l', # plot linha
xlab = "Ano", # nome do eixo x
ylab = "Salário", # nome do eixo y
lwd = 10, # espessura da linha
mgp=c(2.3,0.7,0), # aumenta a posição dos textos dos eixos
cex.lab = 1.4, # aumenta o tamanho do texto dos eixos
cex.axis = 1.4) # aumenta o tamanho dos textos dos números dos eixos
grid() # cria linhas guias
lines(ano, # x
salario.base, # y
lwd = 10) # espessura da linha
lines(ano, # x
salario.estimado, # y
lwd = 4, #espessura da linha
lty = 2, # tipo de linha
col = "red") # cor dos pontos
# criando uma legenda
legend('topleft', # posição da legenda
c("Real", "Estimada"), # texto na legenda
lwd = 7, # espessura das linhas na legenda
lty = c(1, 2), # tipos da linha na legenda
col = c('black', 'red'), # cores das linhas na legenda
cex = 2) # aumenta o tamanho da legenda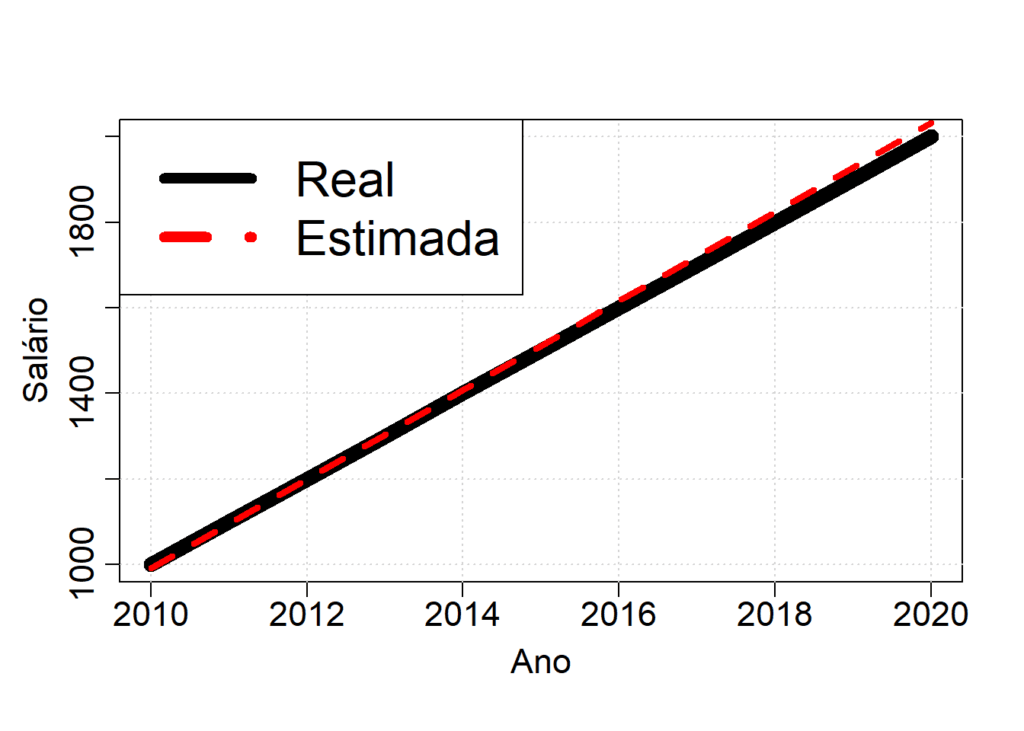
Para predizer futuros salários, nós podemos plotar o valor do salário estimado com o intervalo de confiança de 95%.
anos.futuros = 2010:2030
salario.predito = predict(modelo.GLM, data.frame(ano = anos.futuros), interval = "prediction")
plot(anos.futuros, # x
salario.predito[,1], # y
type = 'l', # plot linha
xlab = "Ano", # nome do eixo x
ylab = "Salário", # nome do eixo y
lwd = 10, # espessura da linha
mgp=c(2.3,0.7,0), # aumenta a posição dos textos dos eixos
cex.lab = 1.4, # aumenta o tamanho do texto dos eixos
cex.axis = 1.4) # aumenta o tamanho dos textos dos números dos eixos
grid() # cria linhas guias
lines(anos.futuros, # x
salario.predito[,1], # y
lwd = 10) # espessura da linha
# limite inferior do intervalo de confiança
lines(anos.futuros, # x
salario.predito[,2], # y
lwd = 4, #espessura da linha
lty = 2, # tipo de linha
col = "red") # cor dos pontos
# limite superior do intervalo de confiança
lines(anos.futuros, # x
salario.predito[,3], # y
lwd = 4, #espessura da linha
lty = 2, # tipo de linha
col = "red") # cor dos pontos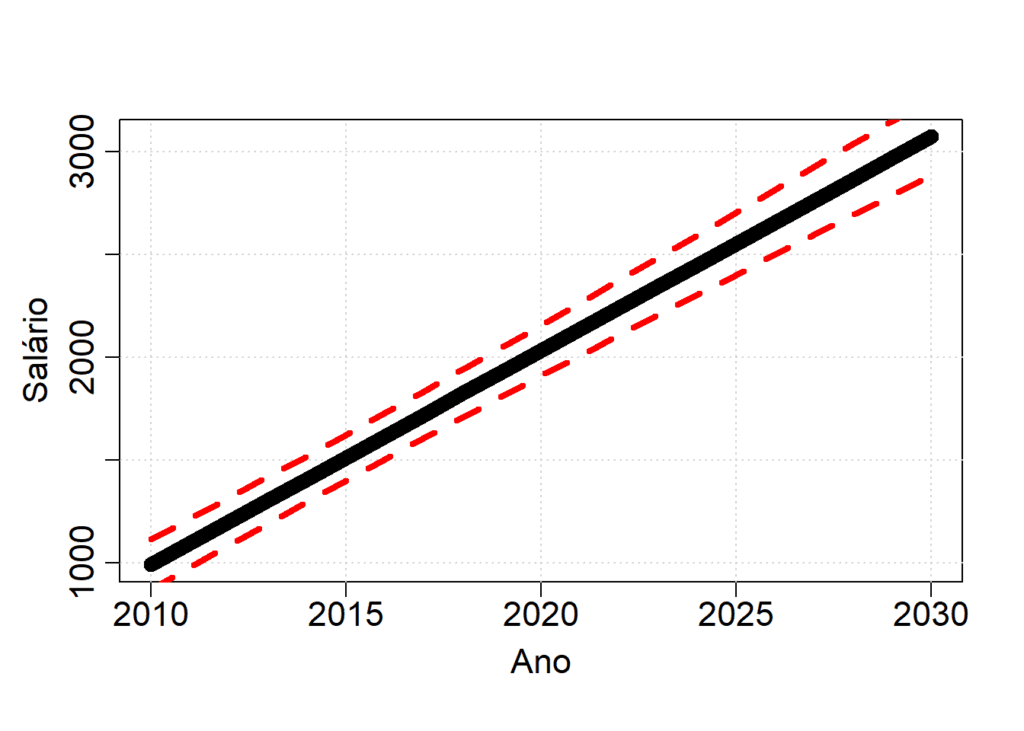
Onde posso ir para aprender mais?
A literatura recomendada é a seguinte:
- Livro que introduz diversas técnicas estatísticas no ambiente R. Zuur AF, Ieno EN, Walker NJ, Saveliev AA, Smith GM. Mixed Effects Models and Extensions in Ecology with R. Springer, New York, 2009.
- Livro que discute a teria de GLMs no R. Pinheiro JC, Bates DM. Mixed-effects models in S and S-PLUS. Springer, New York, 2000.